Implementing a MapReduce Framework with Golang RPC from scratch
I just finished one small piece of work this morning, a MapReduce framework, implemented wit Golang RPC. Before I forget everything, I will document the design and code here. For original source code, it is available at https://github.com/PeterYaoNYU/mit-distributed-sys .

PeterYaoNYU/mit-distributed-sys
I have been coding a lot recently, but not much time has been devoted to writing about what I have done. This is perilous, because I will quickly forget what I have done. Replication is super important for finite state machine as well as leanring computer science.
A MapReduce is a paradigm of abstraction for distributed workflows. The orginal paper published by Google is still wildly influentital today, though 2 decades have gone by. It is divided into 2 phases, a map phase, and a reduce phase. I cannot think of a better description than this image found in the original paper:
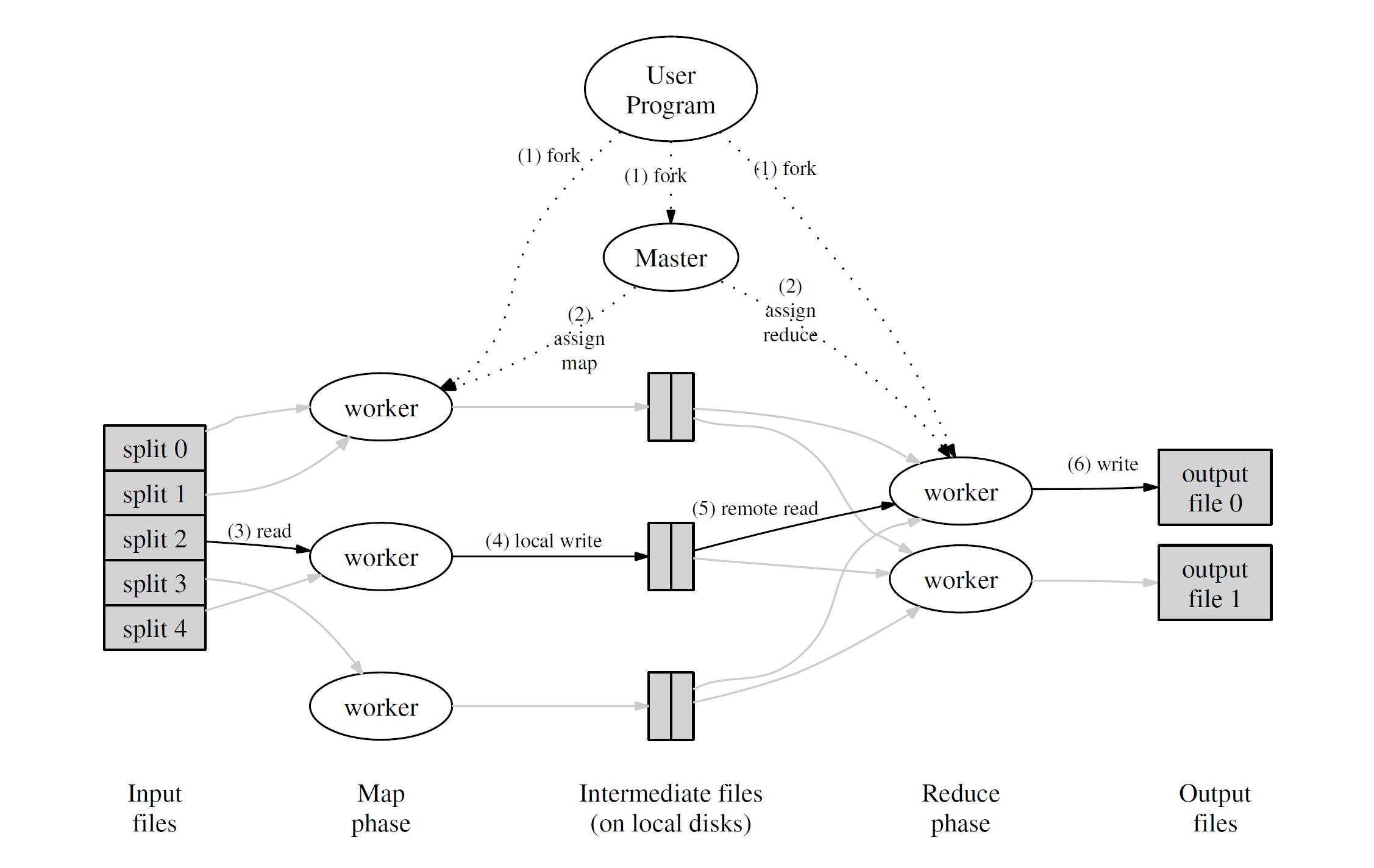
In another words, MR manages and hides all ascpects of distribution.
An Abstract view of a MapReduce job – word count
Input1 -> Map -> a,1 b,1
Input2 -> Map -> b,1
Input3 -> Map -> a,1 c,1
| | |
| | -> Reduce -> c,1
| —–> Reduce -> b,2
———> Reduce -> a,2
- input is (already) split into M files
- MR calls Map() for each input file, produces list of k,v pairs
“intermediate” data
each Map() call is a “task” - when Maps are done,
MR gathers all intermediate v’s for each k,
and passes each key + values to a Reduce call - final output is set of <k,v> pairs from Reduce()s
Implementation of the Worker
The logic for the worker code is more straightforward, and servers as a good starting point. The worker just first acquire the knowledge of how many reduce there are (this decides how many intermediate output each Map should produce), periodically ask for job from the coordinator, wait for the job to arrive, and based on the RPC reply argument, do either Map job or reduce job. After doing the job, report back to the coordinator that the job asked for has been finished, and it can be assigned future tasks then.
1 | func Worker(mapf func(string, string) []KeyValue, |
This is the big framework for the Worker. All we need to do next is to fill in the details. We need to implement:
- the actual map code and reduce code
- report back to the coordinator that the job has been done
- A heartbeat function that peridically asks for more task from the coordinator
- A writer function that output the intermediate values after Map operation to a shared distributed storage system (Like a Google File System)
Let’s fill in the details:
This function is asking for tasks periodically
1 | func requestTask() (reply *RequestTaskReply, succ bool) { |
If the task is a Map task, we do the map, and then write to the disk, then report to the coordinator that the map job has been done.
One detail is that, when we are writing to the shared storage, we are not directly writing to it. To be fault tolerant and avoid problems, first we write to a temporary file, and then we do an atomic rename operation.
Another Detail
When reporting back to the coordinator that a task is finished, we also need to include the host name and PID, because the coordinator needs to be sure that the output comes from someone that is currently responsible for the job, not someone whe was responsible but got timed out, and then came back live again. I made this mistake before, and it is hard to debug, because it may seem like we don’t need a worker PID in the reply struct. Without this, the MapReduce will fail the Crash unit test. Distributed applications are very hard to debug!!!
Each intermediate output is hashed to nReduce partitions, for later consumption of the reduce RPC.
1 | func doMap(mapf func(string, string) []KeyValue, filename string, mapID int, nReduce int) { |
Similar procedures happen with the Reduce part of the worker code:
- get assigned a job
- read in the correspond partition based on RPC reply
- do the reduce call
- write the file back, do atomic rename to be fault tolerant
1 | func reportReduceDone(TaskId int) { |
Implementation of the Coordinator
When a request for task comes to the coordinator, we need to assign tasks:
Now that we have shared data structures in the coordinator, to avoid race condition, we need extensive locking. Just lock everything that is shared, and you will be fine.
The idea is simple: when a request comes in, assign it either a map task or a reduce task, change the task status, and the worker assigned this task (for timeout operations). Also start a go routine waitTask to check for timeout. If timeout happens, then a process is no longer responsible for a certain task. Even if we get result back from the timed out node, we will discard the result (we need to do extrac check of PID in the result we get back).
1 | func (c *Coordinator) RequestTask(args *RequestTaskArgs, reply *RequestTaskReply) error { |
Since we are talking about timeout, here is the implementation:
1 | func (c *Coordinator) waitTask(task *Task) { |
If a timeout happens, which we monitor with a go routine, the state of the task, as well its worker, are changed accordingly. Note how we protect shared data structure with a lock.
If we receive a message, saying that a task has been done, we need to do the following:
- Check the task type, state of the task, and whether the result comes back from someone who is actually responsible for the job.
- Change the task status
- If all tasks (map and reduce) have been finished, get back to the workers, telling them that we have done all the jobs.
Translate the logic into code, and we get:
1 | func (c *Coordinator) ReportTaskDone(args *ReportTaskDoneArgs, reply *ReportTaskDoneReply) error { |
There are some additional details of the code, that I haven’t covered, but the main idea is here. For details, refer back to my source code: https://github.com/PeterYaoNYU/mit-distributed-sys.
Implementing a MapReduce Framework with Golang RPC from scratch
http://peteryaonyu.github.io/2024/01/08/Implementing-a-MapReduce-Framework-with-Golang-from-scratch/